A manutenção de schema de banco de dados é algo importante e delicado em qualquer projeto de desenvolvimento de software. Quando o assunto é banco de dados, todos os desenvolvedores do time precisam estar na mesma página para que possamos realizar mudanças rápidas e com o mínimo de propensão a falhas possível. Com o intuito de atingirmos esses objetivos é importante que o schema do banco de dados esteja protegido pelo nosso controle de versão, e que de preferência, faça parte do processo de Integração Contínua do projeto.
Normalmente o processo de atualização e manutenção de schema de banco de dados é realizado de maneira manual através da criação de scripts SQL e/ou utilização de softwares que geram estes scripts a partir da comparação de dois bancos de dados. Apesar deste processo funcionar em muitos projetos existentes, ele exige muita intervenção manual, o que pode acabar atrasando o lançamento de uma nova versão do sistema e prejudicando os processos de Integração Contínua do projeto.
Uma maneira interessante de abordar a manutenção de schema de banco de dados é através da utilização de migrations. Neste post irei explanar um pouco sobre migrations e demonstrar uma abordagem de como utilizá-las em projetos .NET através de um ótimo framework, o FluentMigrator
O Básico Sobre Migrations
As migrations surgiram como uma alternativa as alterações de banco de dados através da escrita de SQL, bem como uma maneira de evoluir o schema de banco de dados de uma forma gradativa, maneira essa muito válida quando se adota metodologias ágeis. As migrations normalmente são escritas em uma linguagem de programação mais simples para descrever as mudanças no banco de dados, o que normalmente facilita a escrita e a leitura das mesmas.
Esse conceito de migrations foi popularizado pela comunidade Ruby on Rails que o aplica através das Active Record Migrations, de onde o FluentMigrator buscou inspiração.
Implementando o FluentMigrator
A abordagem que irei demonstrar neste post é a que tenho utilizado e recomendado atualmente, mas ela é apenas uma das possíveis maneiras de utilização do FluentMigrator, fique a vontade para implementar da maneira que achar mais interessante para os seus projetos.
Para auxiliar este post eu desenvolvi um pequeno projeto de exemplo que pode ser encontrado em github.com/marcelobalexandre/fluentmigrator-poc.
Como é possível verificar na imagem abaixo eu organizei a estrutura do projeto de exemplo da seguinte maneira:
- Scripts: nesta pasta são mantidos os scripts SQL, nesse caso temos o de criação do banco de dados e um script de criação de tabelas antes da implementação do FluentMigrator.
- MyProject.Data.Migrations: neste projeto temos as migrations organizadas em pastas com o número da versão do projeto a que se referem e o MyProjectMigrator que é responsável por executar as migrações.
- MyProjectMigratorRunner: este projeto é um Console Application que utiliza o MyProjectMigrator para executar as migrações.
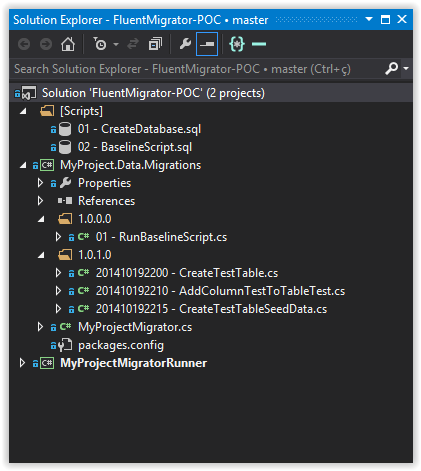
Minha recomendação é criar um projeto separado que conterá as migrations e o nosso Migrator, que no projeto de exemplo chamei de MyProject.Data.Migrations. Basta criar uma Class Library e instalar o Fluent Migrator e o Fluent Migrator Runner utilizando o NuGet.
Criando um Migrator Runner
Para executarmos as migrations podemos utilizar o Command Line Runner (executável do próprio FluentMigrator), o MSBuild, o Rake, ou outros. Eu particularmente prefiro criar um Runner próprio para o projeto, que neste caso chamei de MyProjectMigrator.
Como é possível observar no código abaixo, o MyProjectMigrator é bastante simples e fácil de usar, basta invocar o método Migrate passando como parâmetros a ação que deseja realizar (Up ou Down), a string de conexão com o banco de dados e o MigratorEnvironment. O MigratorEnvironment é um Enumerable que criei para que você possa executar ações diferentes nas migrations dependendo do ambiente, muito útil para por exemplo, criar dados fakes (seeds) no ambiente de desenvolvimento e realizar ações exclusivas para os testes unitários. É importante observar que neste exemplo o MyProjectMigrator espera uma string de conexão para o SQL Server 2012, se o seu caso é diferente basta alterá-lo.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | |
Criando as Migrations
Recomendo a leitura da documentação oficial sobre a criação de migrations que é bem direta e de fácil entendimento, mas basicamente para criamos uma migration é preciso criar uma nova classe que derive da classe abstrata Migration e implemente dois métodos, o Up e o Down. Além disso você devera adicionar o atributo Migration que aceita valores Int64, esse atributo será utilizado para identificar a migration, é baseado nesse atributo que o FluentMigrator vai saber se já rodou ou não a migration.
A classe abstrata Migration nos fornece diversos métodos para manipulação de banco de dados, o que nos permite criar tabelas, criar colunas, renomear colunas, inserir dados, executar um script SQL, dentre outras tarefas. Para conhecer mais e entender melhor esses métodos recomendo a leitura da documentação oficial sobre Fluent Interface.
Algo para se ter em mente na hora de criar uma migration é que não devemos agrupar muitas alterações no banco de dados em apenas uma migration, se você precisa criar duas tabelas novas por exemplo, faça isso em duas migrations separadas e não em apenas uma. Outra boa prática é em relação aos nomes das migration, adote um padrão claro para que todo o time entenda de maneira fácil o que determinada migration irá fazer apenas olhando o nome da mesma, se sua migration irá criar uma tabela Clients por exemplo, uma boa opção seria CreateClientsTable. Outra dica é utilizar o padrão YYYYMMDDHHMM no atributo identificador da migration, dessa maneira conseguimos saber rapidamente quando foi desenvolvida e diminuímos o risco de dois desenvolvedores criarem uma migration com o mesmo identificador.
Criei alguns exemplos de como uso e organizo migrations no projeto de exemplo, mas lembre-se que mais importante que usar esse ou aquele padrão, é utilizar algum e fazer com que o time todo o siga.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
Executando as Migrations
Como visto anteriormente eu criei um Migrator Runner próprio chamado MyProjectMigrator, ele pode ser utilizado para rodar as migrations nos seus projetos de teste, em uma Console Application (como é o caso do projeto de exemplo) ou em um aplicativo com uma interface gráfica amigável. Como é possível observar no projeto de exemplo a utilização do MyProjectMigrator é bastante simples e pode ser customizada, mas se preferir outras maneiras de rodar as migrations, dê uma conferida na ddocumentação oficial sobre Migration Runners.
Após a execução das migrations, como pode ser verificado nas imagens abaixo, o FluentMigrator irá criar uma tabela VersionInfo no seu banco de dados onde salvará a identificação das migrations que foram executadas, com a data e hora da execução das mesmas bem como sua descrição, que nada mais é do que o nome das classes.
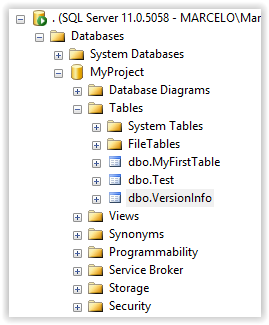
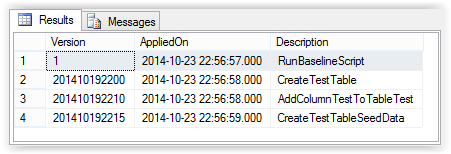
Conclusão
O que gosto nesta abordagem é a facilidade que qualquer desenvolvedor têm de realizar uma alteração no banco de dados, bem como compreender o que determinada migration, criada por outro desenvolvedor, irá realizar. A maneira que o FluentMigrator controla quais migrations foram executadas pelo número identificador, traz mais segurança na hora de atualizar o banco de dados de um cliente, e tudo isso permite que o processo de Integração Contínua funcione de maneira adequada. Ao invés de termos a necessidade de alguém executar algum software que gere um script de alteração de banco de dados, de maneira manual, a cada nova versão do sistema, basta fazer com que um Gerenciador ou Atualizar de Banco de Dados do projeto seja compilado com a versão correta do projeto que contêm as migrations.
Apesar de minha preferência pela utilização de migrations, é importante que você estude e adote a estratégia mais importante para o seu projeto. Se sua opção for utilizar migrations, não fique preso na maneira que eu utilizo, adapte para que funcione melhor para o seu projeto. Enfim, o que gostaria de passar neste post era isso, por favor deixe seu comentário com críticas, dúvidas ou sugestões.